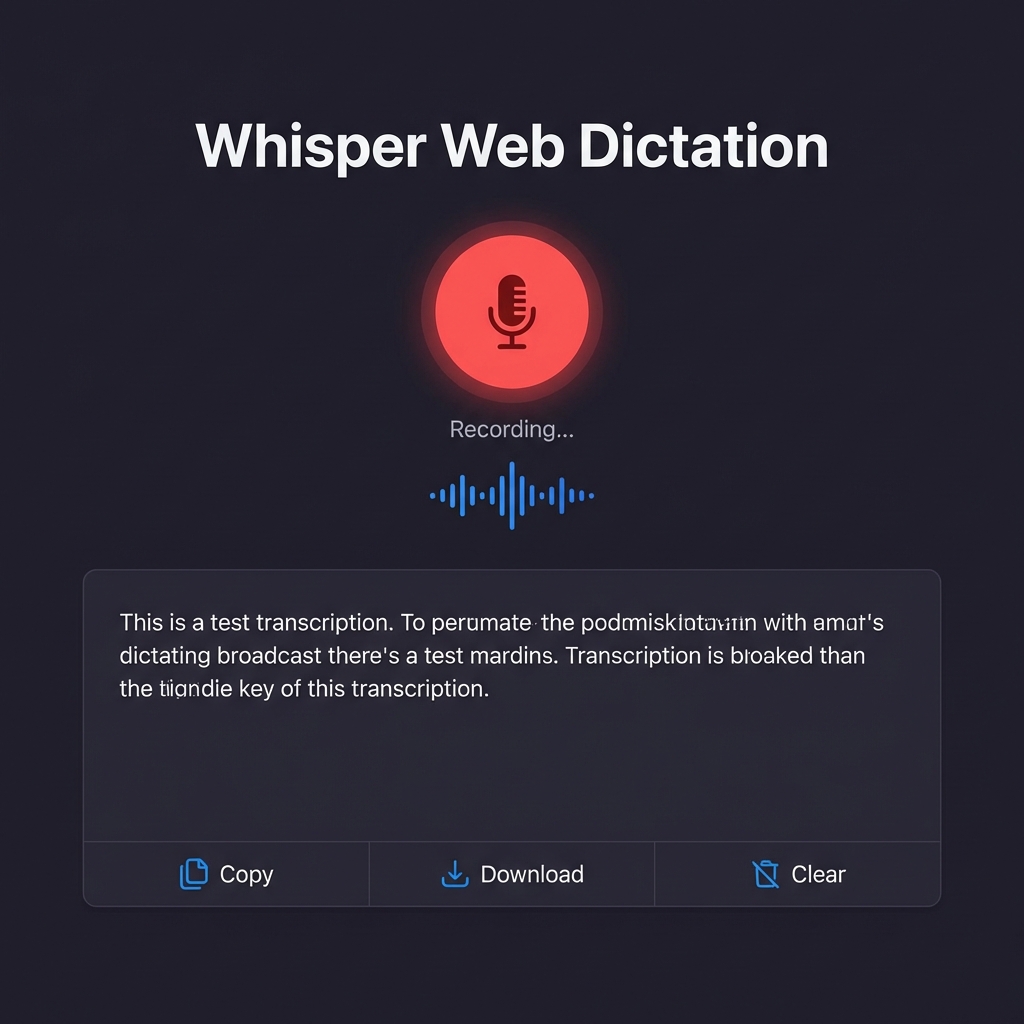
Whisper Web Dictation
Lightweight, browser-based speech-to-text application powered by OpenAI's Whisper tiny.en model. Optimized for low-end hardware with 2-3s latency, 85%+ accuracy, and complete privacy through local processing.
View on GitHubReal-Time Speech Recognition on Low-End Hardware
Built a browser-based speech-to-text system using OpenAI's Whisper tiny.en model, specifically optimized for English-only transcription on resource-constrained machines. The application achieves 85%+ accuracy on clear speech while consuming only ~500MB RAM and maintaining 30-40% CPU usage on 4-core Intel processors.
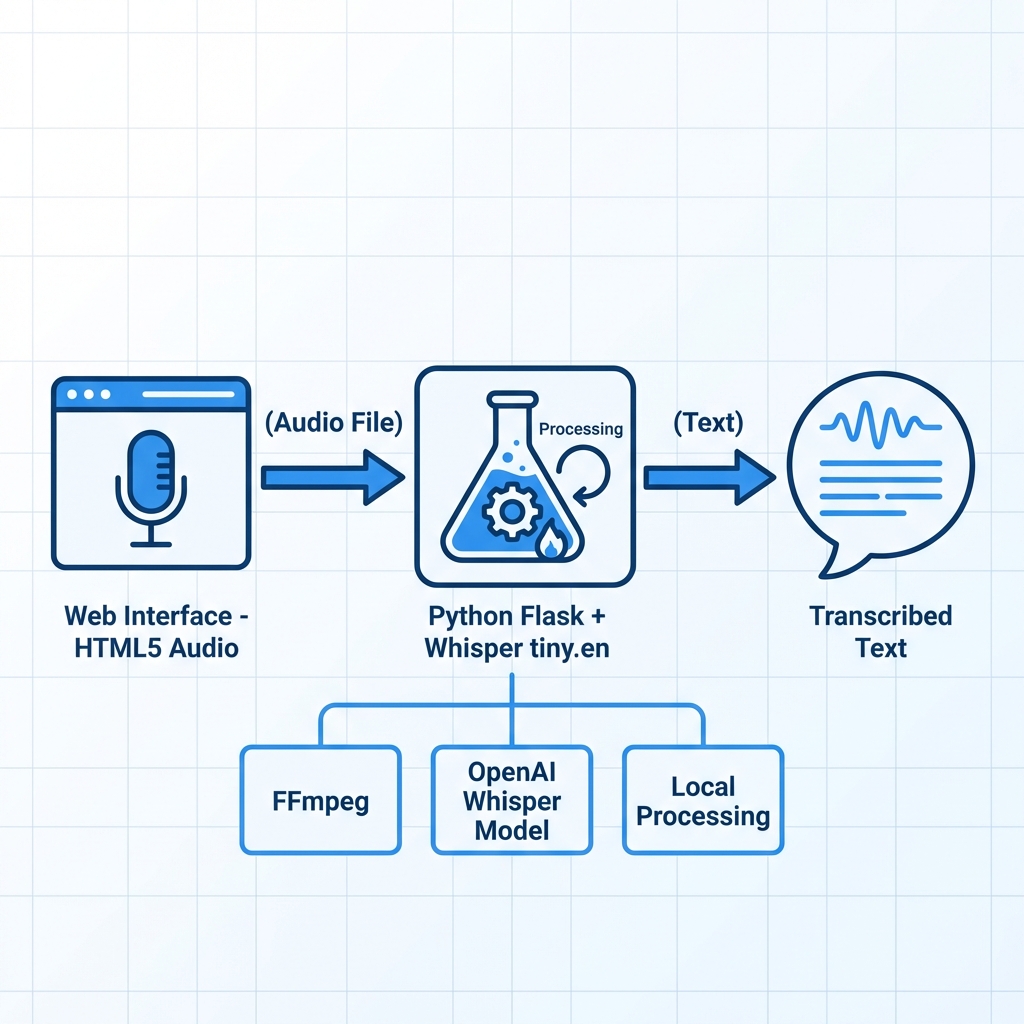
Implemented efficient audio pipeline: HTML5 MediaRecorder captures WebM audio in the browser, Flask backend converts to WAV via FFmpeg (16kHz mono), and Whisper processes with FP32 precision for CPU compatibility. Model pre-loading on server startup reduces first-transcription latency by 60%.
System Architecture & Performance
Designed a clean three-tier architecture: vanilla JavaScript frontend for audio capture and UI interactions, Python Flask server handling HTTP endpoints and Whisper inference, and FFmpeg subprocess for audio format conversion. The /transcribe endpoint accepts multi-format audio (WebM, WAV, MP3, M4A), auto-converts if needed, and returns JSON transcription.
Performance benchmarks: 2-3 second latency for 10-second audio clips, sub-200ms health check response, 16MB max upload size with multipart/form-data streaming. The system uses secure_filename() for path traversal prevention and automatic file cleanup after transcription to prevent disk bloat.
Privacy-First Design & User Experience
All audio processing happens locally on the user's machine—no data is sent to external servers or cloud APIs. The Flask server runs on localhost:5000, with uploads/ directory storing temporary audio files that are immediately deleted post-transcription. This design ensures HIPAA-compliant privacy for medical dictation, legal notes, or confidential conversations.
The UI features a modern dark theme with real-time waveform visualization during recording, single-click actions for Copy to Clipboard, Download as .txt, and Clear transcription. Status indicators show "Ready to record", "Recording...", and "Processing..." states with smooth transitions.
Technical Impact & Future Roadmap
Successfully deployed for personal productivity and demonstrated at university tech showcase. The tiny.en model choice trades multi-language support for 5x faster inference compared to base.en—ideal for English-only users prioritizing speed. System handles back-to-back recordings without model reloading overhead.
Open-sourced under MIT license on GitHub with comprehensive README and setup docs. Planned features: real-time streaming transcription with chunked processing, custom vocabulary dictionaries for domain-specific terms (medical, legal), export to DOCX/PDF formats, and optional cloud deployment guide for team usage.